(原标题:深耕人工智能研究,度小满自研轩辕模型在CLUE1。1分类任务中排名首位)
如今,人工智能在金融各大场景中的应用不断加深,为金融行业带来诸多改变。作为早已在人工智能领域布局的头部金融科技企业,度小满近年来不断攻克人工智能技术方面的难题,积累了丰厚的技术底蕴。日前,其自主研发的轩辕(XuanYuan)预训练模型在CLUE1。1分类任务中夺得首位,展现了度小满在人工智能技术方面的雄厚实力。
度小满轩辕预训练模型CLUE1。1分类任务中“力压群雄”排名首位
自然语言处理是人工智能皇冠上的明珠,近日,度小满AI-Lab让人类摘得明珠的步伐又前进了一步。据中文语言理解领域的权威测评基准官网公布,度小满AI-Lab研发的轩辕(XuanYuan)预训练模型在CLUE1。1分类任务中“力压群雄”获得了排名第一的好成绩。距离人类“表现”仅差3。38分!
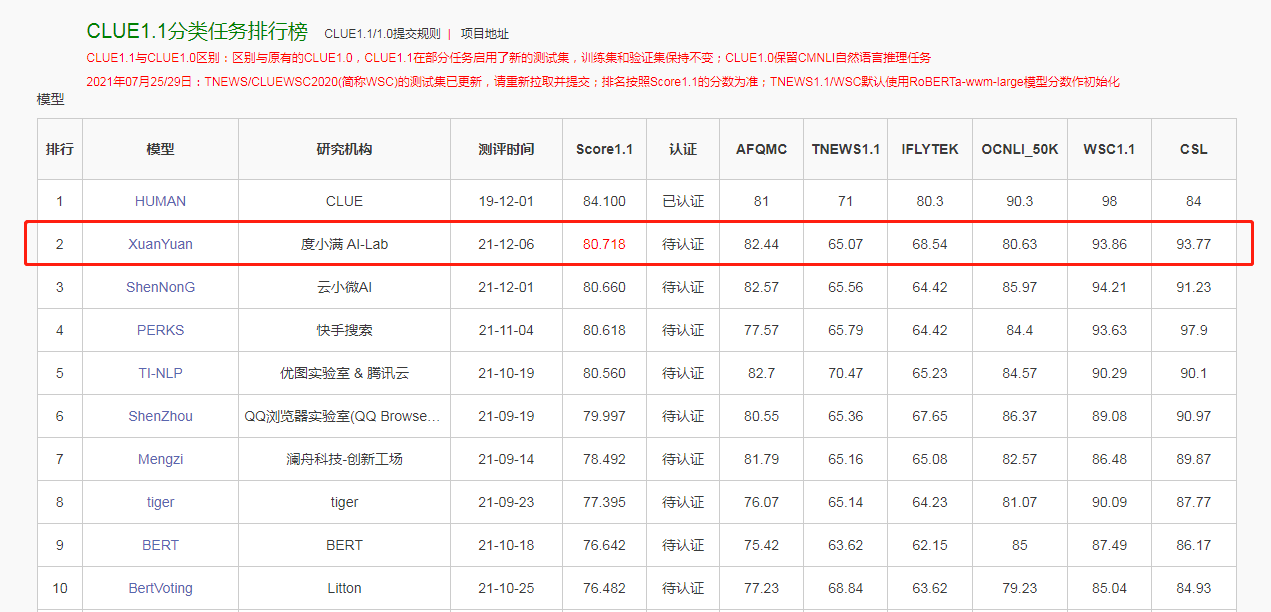
CLUE是中文语言理解领域最具权威性的测评基准之一,涵盖了文本相似度、分类、阅读理解共10项语义分析和理解类子任务。其中,分类任务需要解决6个问题,例如传统图像分类,文本匹配,关键词分类等等,能够全方面衡量模型性能。该榜单竞争激烈,几乎是业内兵家必争之地,例如快手搜索、优图实验室 & 腾讯云等等研究机构也都提交了比赛方案。
据悉,位居榜首的“轩辕”是基于Transformer架构的预训练语言模型,涵盖了金融、新闻、百科、网页等多领域大规模数据。因此,该模型“内含”的数据更全面,更丰富,面向的领域更加广泛。
度小满加强人工智能技术研究
预训练模型是一种迁移学习的应用,可以利用几乎无限的文本,学习输入句子的每一个成员的上下文相关的表示,它隐式地学习到了通用的语法语义知识。换句话说,预训练模型把通用人类的语言知识先学会,然后再代入到某个具体任务。它可以将从开放领域学到的知识迁移到下游任务,以改善低资源任务;还可以使自然语言处理由原来的手工调参、依靠 ML 专家的阶段,进入到可以大规模、可复制的大工业施展的阶段。
目前,除了预训练,度小满AI-Lab在文本分类、信息抽取和技术资源等方向亦有布局。在战略上会有两点侧重:首先加强自身的数据生态建设,合法合规使用用户数据,解决数据孤岛;其次通过产学研相结合,布局前沿技术,落地金融场景业务。
据了解,度小满已与北京大学光华管理学院成立了“金融科技联合实验室”,和西安交大成立了“西安交通大学-度小满金融人工智能联合研究中心”,并与中国科学院自动化研究所共建博士后工作站,共同开展人工智能及相关领域的博士后联合招收培养。
度小满始终关注金融行业发展,注重人工智能等各种新兴技术的研发和创新应用,持续提升自身的核心技术竞争实力,同时为行业发展不断贡献力量。相信在度小满等金融科技企业的共同助力下,新兴技术将更加深入运用到金融服务各大领域,持续推动行业创新变革。